2. DeePMD-kit Quick Start Tutorial#

©️ Copyright 2024 @ Authors
📖 Getting Started Guide
Licensing Agreement: This work is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
This document can be executed directly on the Bohrium Notebook. To begin,you can click the Open in Bohrium button above to quickly run this document in Bohrium.
After opening Bohrium Notebook, click the button connect .We have already set up the recommended image and the recommended machine type for you.
This is a quick start guide for “Deep Potential” molecular dynamics using DeePMD-kit, through which you can quickly understand the paradigm cycle that DeePMD-kit operates in and apply it to your projects.
Deep Potential is the convergence of machine learning and physical principles, presenting a new computational paradigm as shown in the figure below.

Figure | A new computational paradigm, composed of Molecular Modeling, Machine Learning, and High-Performance Computing (HPC).
2.1. Task#
Mastering the paradigm cycle of using DeePMD-kit to establish deep potential molecular dynamics models, and following a complete case to learn how to apply it to molecular dynamics tasks.
By the end of this tutorial, you will be able to:
Prepare the formataive dataset and running scripts for training with DeePMD-kit;
Train, freeze, and test DeePMD-kit models;
Use DeePMD-kit in LAMMPS for calculations;
Work through this tutorial. It will take you 20 minutes, max!
2.2. Background#
In this tutorial, we will take the gaseous methane molecule as an example to provide a detailed introduction to the training and application of the Deep Potential (DP) model.
DeePMD-kit is a software tool that employs neural networks to fit potential energy models based on first-principles data for molecular dynamics simulations. Without manual intervention, it can end-to-end transform the data provided by users into a deep potential model in a matter of hours. This model can seamlessly integrate with common molecular dynamics simulation software (like LAMMPS and OpenMM).
DeePMD-kit significantly elevates the limits of molecular dynamics through high-performance computing and machine learning, achieving system scales of up to hundreds of millions of atoms while still maintaining the high accuracy of “ab initio” calculations. The simulation time scale is improved by at least 1000 times compared to traditional methods. Its achievements earned the 2020 ACM Gordon Bell Prize, one of the highest honors in the field of high-performance computing, and it has been used by over a thousand research groups in physics, chemistry, materials science, biology, and other fields globally.

For more detailed usage, you can refer to the DeePMD-kit’s documentation as a comprehensive reference.
In this case, the Deep Potential (DP) model was generated using the DeePMD-kit package.
2.3. Practice#
2.3.1. Data Preparation#
We have prepared the initial data for \(CH_4\) required to run DeePMD-kit computations and placed it in the DeePMD-kit_Tutorial folder. You can view the corresponding files by clicking on the dataset on the left side:
import os
# Define the dataset URL and the paths
dataset_url = "https://bohrium-api.dp.tech/ds-dl/DeePMD-kit-Tutorial-a8z5-v1.zip"
zip_file_name = "DeePMD-kit-Tutorial-a8z5-v1.zip"
dataset_directory = "DeePMD-kit_Tutorial"
local_zip_path = f"/personal/{zip_file_name}"
extract_path = "/personal/"
# Check if the dataset directory exists to avoid re-downloading and re-extracting
if not os.path.isdir(f"{extract_path}{dataset_directory}"):
# Download and extract if not exists
if not os.path.isfile(local_zip_path):
print("Downloading dataset...")
!wget -q -O {local_zip_path} {dataset_url}
print("Extracting dataset...")
!unzip -q -n {local_zip_path} -d {extract_path}
else:
print("Dataset is already downloaded and extracted.")
# Change the current working directory
os.chdir(f"{extract_path}")
print(f"Current path is: {os.getcwd()}")
Dataset is already downloaded and extracted.
Current path is: /personal
Let’s take a look at the downloaded DeePMD-kit_Tutorial folder.
! tree DeePMD-kit_Tutorial -L 1
DeePMD-kit_Tutorial
├── 00.data
├── 01.train
├── 01.train.finished
├── 02.lmp
└── 02.lmp.finished
5 directories, 0 files
There are 3 subfolders under the DeePMD-kit_Tutorial folder: 00.data, 01.train, and 02.lmp.
The 00.data folder is used to store training and testing data.
The 01.train folder contains example scripts for training models using DeePMD-kit.
The 01.train.finished folder includes the complete results of the training process.
The 02.lmp folder contains example scripts for molecular dynamics simulations using LAMMPS.
Let’s first take a look at the DeePMD-kit_Tutorial/00.data folder.
! tree DeePMD-kit_Tutorial/00.data -L 1
DeePMD-kit_Tutorial/00.data
├── abacus_md
├── training_data
└── validation_data
3 directories, 0 files
DeePMD-kit’s training data originates from first-principles calculation data, including atomic types, simulation cells, atomic coordinates, atomic forces, system energies, and virials.

In the 00.data folder, there is only the abacus_md folder, which contains data obtained through ab initio Molecular Dynamics (AIMD) simulations using ABACUS. In this tutorial, we have already completed the ab initio molecular dynamics calculations for the methane molecule for you.
Detailed information about ABACUS can be found in its documentation.
DeePMD-kit uses a compressed data format. All training data should first be converted into this format before they can be used in DeePMD-kit. This data format is explained in detail in the DeePMD-kit manual, which can be found on DeePMD-kit’s GitHub.
We provide a convenient tool dpdata, which can convert data generated by VASP, CP2K, Gaussian, Quantum Espresso, ABACUS, and LAMMPS into DeePMD-kit’s compressed format.
A snapshot of a molecular system that contains computational data information is called a frame. A data system comprises many frames sharing the same number of atoms and atom types.
For example, a molecular dynamics trajectory can be converted into a data system, where each timestep corresponds to one frame in the system.
Next, we use the dpdata tool to randomly split the data in abacus_md into training and validation data.
import dpdata
import numpy as np
# load data of abacus/md format
data = dpdata.LabeledSystem("DeePMD-kit_Tutorial/00.data/abacus_md", fmt="abacus/md")
print(f"# the data contains {len(data)} frames")
# random choose 40 index for validation_data
rng = np.random.default_rng()
index_validation = rng.choice(201, size=40, replace=False)
# other indexes are training_data
index_training = list(set(range(201)) - set(index_validation))
data_training = data.sub_system(index_training)
data_validation = data.sub_system(index_validation)
# all training data put into directory:"training_data"
data_training.to_deepmd_npy("DeePMD-kit_Tutorial/00.data/training_data")
# all validation data put into directory:"validation_data"
data_validation.to_deepmd_npy("DeePMD-kit_Tutorial/00.data/validation_data")
print(f"# the training data contains {len(data_training)} frames")
print(f"# the validation data contains {len(data_validation)} frames")
# the data contains 201 frames
# the training data contains 161 frames
# the validation data contains 40 frames
As you can see, 161 frames are picked as training data, and the other 40 frames are validation dat.
Let’s take another look at the 00.data folder, where new files have been generated, which are the training and validation sets required for Deep Potential training with DeePMD-kit.
! tree DeePMD-kit_Tutorial/00.data/ -L 1
DeePMD-kit_Tutorial/00.data/
├── abacus_md
├── training_data
└── validation_data
3 directories, 0 files
! tree DeePMD-kit_Tutorial/00.data/training_data -L 1
DeePMD-kit_Tutorial/00.data/training_data
├── set.000
├── type.raw
└── type_map.raw
1 directory, 2 files
The functions of these files are as follows:
set.000: It is a directory that contains compressed format data (NumPy compressed arrays).
type.raw: It is a file that contains the types of atoms (represented as integers).
type_map.raw: It is a file that contains the names of the types of atoms.
Let’s take a look at these files.
Let’s have a look at type.raw:
! cat DeePMD-kit_Tutorial/00.data/training_data/type.raw
0
0
0
0
1
This tells us there are 5 atoms in this example, 4 atoms represented by type “0”, and 1 atom represented by type “1”. Sometimes one needs to map the integer types to atom name. The mapping can be given by the file type_map.raw
! cat DeePMD-kit_Tutorial/00.data/training_data/type_map.raw
H
C
This tells us the type “0” is named by “H”, and the type “1” is named by “C”.
More detailed documentation on using dpdata for data conversion can be found here
2.3.2. Prepare input script#
Once the data preparation is done, we can go on with training. Now go to the training directory. DeePMD-kit requires a json format file to specify parameters for training.
# Check dargs version and Install
!pip show dargs || pip install --upgrade dargs
# Show input.json
from deepmd.utils.argcheck import gen_args
from dargs.notebook import JSON
with open("./DeePMD-kit_Tutorial/01.train/input.json") as f:
JSON(f.read(), gen_args())
{ "_comment": "that's all", "model"model: type: dict
: { "type_map"type_map: type: typing.list[str], optional
A list of strings. Give the name to each type of atoms. It is noted that the number of atom type of training system must be less than 128 in a GPU environment. If not given, type.raw in each system should use the same type indexes, and type_map.raw will take no effect.
: [
"H",
"C"
], "descriptor"descriptor: type: dict
The descriptor of atomic environment.
: { "type"type:type: str
The type of the descriptor. See explanation below.
- loc_frame: Defines a local frame at each atom, and the compute the descriptor as local coordinates under this frame.
- se_e2_a: Used by the smooth edition of Deep Potential. The full relative coordinates are used to construct the descriptor.
- se_e2_r: Used by the smooth edition of Deep Potential. Only the distance between atoms is used to construct the descriptor.
- se_e3: Used by the smooth edition of Deep Potential. The full relative coordinates are used to construct the descriptor. Three-body embedding will be used by this descriptor.
- se_a_tpe: Used by the smooth edition of Deep Potential. The full relative coordinates are used to construct the descriptor. Type embedding will be used by this descriptor.
- se_atten: Used by the smooth edition of Deep Potential. The full relative coordinates are used to construct the descriptor. Attention mechanism will be used by this descriptor.
- se_atten_v2: Used by the smooth edition of Deep Potential. The full relative coordinates are used to construct the descriptor. Attention mechanism with new modifications will be used by this descriptor.
- se_a_mask: Used by the smooth edition of Deep Potential. It can accept a variable number of atoms in a frame (Non-PBC system). aparam are required as an indicator matrix for the real/virtual sign of input atoms.
- hybrid: Concatenate of a list of descriptors as a new descriptor.
: "se_e2_a", "sel"sel: type: str | typing.list[int], optional, default: auto
This parameter set the number of selected neighbors for each type of atom. It can be:
- list[int]. The length of the list should be the same as the number of atom types in the system. sel[i] gives the selected number of type-i neighbors. sel[i] is recommended to be larger than the maximally possible number of type-i neighbors in the cut-off radius. It is noted that the total sel value must be less than 4096 in a GPU environment.
- str. Can be "auto:factor" or "auto". "factor" is a float number larger than 1. This option will automatically determine the sel. In detail it counts the maximal number of neighbors with in the cutoff radius for each type of neighbor, then multiply the maximum by the "factor". Finally the number is wraped up to 4 divisible. The option "auto" is equivalent to "auto:1.1".
: "auto", "rcut_smth"rcut_smth: type: float, optional, default: 0.5
Where to start smoothing. For example the 1/r term is smoothed from rcut to rcut_smth
: 0.5, "rcut"rcut: type: float, optional, default: 6.0
The cut-off radius.
: 6.0, "neuron"neuron: type: typing.list[int], optional, default: [10, 20, 40]
Number of neurons in each hidden layers of the embedding net. When two layers are of the same size or one layer is twice as large as the previous layer, a skip connection is built.
: [
25,
50,
100
], "resnet_dt"resnet_dt: type: bool, optional, default: False
Whether to use a "Timestep" in the skip connection
: false, "axis_neuron"axis_neuron: type: int, optional, default: 4, alias: n_axis_neuron
Size of the submatrix of G (embedding matrix).
: 16, "seed"seed: type: NoneType | int, optional
Random seed for parameter initialization
: 1, "_comment": " that's all" }, "fitting_net"fitting_net: type: dict
The fitting of physical properties.
: { "neuron"neuron: type: typing.list[int], optional, default: [120, 120, 120], alias: n_neuron
The number of neurons in each hidden layers of the fitting net. When two hidden layers are of the same size, a skip connection is built.
: [
240,
240,
240
], "resnet_dt"resnet_dt: type: bool, optional, default: True
Whether to use a "Timestep" in the skip connection
: true, "seed"seed: type: NoneType | int, optional
Random seed for parameter initialization of the fitting net
: 1, "_comment": " that's all" }, "_comment": " that's all" }, "learning_rate"learning_rate: type: dict, optional
The definition of learning rate
: { "type"type:type: str, default: exp
The type of the learning rate.
: "exp", "decay_steps"decay_steps: type: int, optional, default: 5000
The learning rate is decaying every this number of training steps.
: 50, "start_lr"start_lr: type: float, optional, default: 0.001
The learning rate at the start of the training.
: 0.001, "stop_lr"stop_lr: type: float, optional, default: 1e-08
The desired learning rate at the end of the training.
: 3.51e-08, "_comment": "that's all" }, "loss"loss: type: dict, optional
The definition of loss function. The loss type should be set to tensor, ener or left unset.
: { "type"type:type: str, default: ener
The type of the loss. When the fitting type is ener, the loss type should be set to ener or left unset. When the fitting type is dipole or polar, the loss type should be set to tensor.
: "ener", "start_pref_e"start_pref_e: type: float | int, optional, default: 0.02
The prefactor of energy loss at the start of the training. Should be larger than or equal to 0. If set to none-zero value, the energy label should be provided by file energy.npy in each data system. If both start_pref_e and limit_pref_e are set to 0, then the energy will be ignored.
: 0.02, "limit_pref_e"limit_pref_e: type: float | int, optional, default: 1.0
The prefactor of energy loss at the limit of the training, Should be larger than or equal to 0. i.e. the training step goes to infinity.
: 1, "start_pref_f"start_pref_f: type: float | int, optional, default: 1000
The prefactor of force loss at the start of the training. Should be larger than or equal to 0. If set to none-zero value, the force label should be provided by file force.npy in each data system. If both start_pref_f and limit_pref_f are set to 0, then the force will be ignored.
: 1000, "limit_pref_f"limit_pref_f: type: float | int, optional, default: 1.0
The prefactor of force loss at the limit of the training, Should be larger than or equal to 0. i.e. the training step goes to infinity.
: 1, "start_pref_v"start_pref_v: type: float | int, optional, default: 0.0
The prefactor of virial loss at the start of the training. Should be larger than or equal to 0. If set to none-zero value, the virial label should be provided by file virial.npy in each data system. If both start_pref_v and limit_pref_v are set to 0, then the virial will be ignored.
: 0, "limit_pref_v"limit_pref_v: type: float | int, optional, default: 0.0
The prefactor of virial loss at the limit of the training, Should be larger than or equal to 0. i.e. the training step goes to infinity.
: 0, "_comment": " that's all" }, "training"training: type: dict
The training options.
: { "training_data"training_data: type: dict, optional
Configurations of training data.
: { "systems"systems: type: str | typing.list[str]
The data systems for training. This key can be provided with a list that specifies the systems, or be provided with a string by which the prefix of all systems are given and the list of the systems is automatically generated.
: [
"../00.data/training_data"
], "batch_size"batch_size: type: str | typing.list[int] | int, optional, default: auto
This key can be
- list: the length of which is the same as the systems_. The batch size of each system is given by the elements of the list.
- int: all systems_ use the same batch size.
- string "auto": automatically determines the batch size so that the batch_size times the number of atoms in the system is no less than 32.
- string "auto:N": automatically determines the batch size so that the batch_size times the number of atoms in the system is no less than N.
- string "mixed:N": the batch data will be sampled from all systems and merged into a mixed system with the batch size N. Only support the se_atten descriptor.
If MPI is used, the value should be considered as the batch size per task.
: "auto", "_comment": "that's all" }, "validation_data"validation_data: type: NoneType | dict, optional, default: None
Configurations of validation data. Similar to that of training data, except that a numb_btch argument may be configured
: { "systems"systems: type: str | typing.list[str]
The data systems for validation. This key can be provided with a list that specifies the systems, or be provided with a string by which the prefix of all systems are given and the list of the systems is automatically generated.
: [
"../00.data/validation_data"
], "batch_size"batch_size: type: str | typing.list[int] | int, optional, default: auto
This key can be
- list: the length of which is the same as the systems_. The batch size of each system is given by the elements of the list.
- int: all systems_ use the same batch size.
- string "auto": automatically determines the batch size so that the batch_size times the number of atoms in the system is no less than 32.
- string "auto:N": automatically determines the batch size so that the batch_size times the number of atoms in the system is no less than N.
: "auto", "numb_btch"numb_btch: type: int, optional, default: 1, alias: numb_batch
An integer that specifies the number of batches to be sampled for each validation period.
: 1, "_comment": "that's all" }, "numb_steps"numb_steps: type: int, alias: stop_batch
Number of training batch. Each training uses one batch of data.
: 10000, "seed"seed: type: NoneType | int, optional
The random seed for getting frames from the training data set.
: 10, "disp_file"disp_file: type: str, optional, default: lcurve.out
The file for printing learning curve.
: "lcurve.out", "disp_freq"disp_freq: type: int, optional, default: 1000
The frequency of printing learning curve.
: 200, "save_freq"save_freq: type: int, optional, default: 1000
The frequency of saving check point.
: 1000, "_comment": "that's all" }}DeePMD-kit requires a json format file to specify parameters for training.
In the model section, the parameters of embedding and fitting networks are specified.
"model":{
"type_map": ["H", "C"],
"descriptor":{
"type": "se_e2_a",
"rcut": 6.00,
"rcut_smth": 0.50,
"sel": "auto",
"neuron": [25, 50, 100],
"resnet_dt": false,
"axis_neuron": 16,
"seed": 1,
"_comment": "that's all"
},
"fitting_net":{
"neuron": [240, 240, 240],
"resnet_dt": true,
"seed": 1,
"_comment": "that's all"
},
"_comment": "that's all"'
},
The explanation for some of the parameters is as follows:
Parameter | Expiation |
|---|---|
type_map | the name of each type of atom |
descriptor > type | the type of descriptor |
descriptor > rcut | cut-off radius |
descriptor > rcut_smth | where the smoothing starts |
descriptor > sel | the maximum number of type i atoms in the cut-off radius |
descriptor > neuron | size of the embedding neural network |
descriptor > axis_neuron | the size of the submatrix of G (embedding matrix) |
fitting_net > neuron | size of the fitting neural network |
The se_e2_a descriptor is used to train the DP model. The item neurons set the size of the descriptors and fitting network to [25, 50, 100] and [240, 240, 240], respectively. The components in local environment to smoothly go to zero from 0.5 to 6 Å.
The following are the parameters that specify the learning rate and loss function.
"learning_rate" :{
"type": "exp",
"decay_steps": 50,
"start_lr": 0.001,
"stop_lr": 3.51e-8,
"_comment": "that's all"
},
"loss" :{
"type": "ener",
"start_pref_e": 0.02,
"limit_pref_e": 1,
"start_pref_f": 1000,
"limit_pref_f": 1,
"start_pref_v": 0,
"limit_pref_v": 0,
"_comment": "that's all"
},
In the loss function, pref_e increases from 0.02 to 1, and pref_f decreases from 1000 to 1 progressively, which means that the force term dominates at the beginning, while energy and virial terms become important at the end. This strategy is very effective and reduces the total training time. pref_v is set to 0 , indicating that no virial data are included in the training process. The starting learning rate, stop learning rate, and decay steps are set to 0.001, 3.51e-8, and 50, respectively. The model is trained for 10000 steps.
The training parameters are given in the following
"training" : {
"training_data": {
"systems": ["../00.data/training_data"],
"batch_size": "auto",
"_comment": "that's all"
},
"validation_data":{
"systems": ["../00.data/validation_data/"],
"batch_size": "auto",
"numb_btch": 1,
"_comment": "that's all"
},
"numb_steps": 10000,
"seed": 10,
"disp_file": "lcurve.out",
"disp_freq": 200,
"save_freq": 10000,
},
More detailed docs about Data conversion can be found here
2.3.3. Train a model#
After the training script is prepared, we can start the training with DeePMD-kit by simply running
# ########## Time Warning: 120 secs,C32_CPU ; 13 mins ,C2_CPU ##########
! cd DeePMD-kit_Tutorial/01.train/ && dp train input.json
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/tensorflow/python/compat/v2_compat.py:107: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
non-resource variables are not supported in the long term
WARNING:root:To get the best performance, it is recommended to adjust the number of threads by setting the environment variables OMP_NUM_THREADS, TF_INTRA_OP_PARALLELISM_THREADS, and TF_INTER_OP_PARALLELISM_THREADS. See https://deepmd.rtfd.io/parallelism/ for more information.
DEEPMD INFO Calculate neighbor statistics... (add --skip-neighbor-stat to skip this step)
DEEPMD INFO training data with min nbor dist: 1.0460506586976848
DEEPMD INFO training data with max nbor size: [4 1]
DEEPMD INFO _____ _____ __ __ _____ _ _ _
DEEPMD INFO | __ \ | __ \ | \/ || __ \ | | (_)| |
DEEPMD INFO | | | | ___ ___ | |__) || \ / || | | | ______ | | __ _ | |_
DEEPMD INFO | | | | / _ \ / _ \| ___/ | |\/| || | | ||______|| |/ /| || __|
DEEPMD INFO | |__| || __/| __/| | | | | || |__| | | < | || |_
DEEPMD INFO |_____/ \___| \___||_| |_| |_||_____/ |_|\_\|_| \__|
DEEPMD INFO Please read and cite:
DEEPMD INFO Wang, Zhang, Han and E, Comput.Phys.Comm. 228, 178-184 (2018)
DEEPMD INFO Zeng et al, J. Chem. Phys., 159, 054801 (2023)
DEEPMD INFO See https://deepmd.rtfd.io/credits/ for details.
DEEPMD INFO installed to: /root/miniconda3/envs/deepmd
DEEPMD INFO source : v2.2.7
DEEPMD INFO source branch: HEAD
DEEPMD INFO source commit: 839f4fe7
DEEPMD INFO source commit at: 2023-10-27 21:10:24 +0800
DEEPMD INFO build float prec: double
DEEPMD INFO build variant: cpu
DEEPMD INFO build with tf inc: /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/tensorflow/include;/root/miniconda3/envs/deepmd/lib/python3.10/site-packages/tensorflow/../../../../include
DEEPMD INFO build with tf lib:
DEEPMD INFO ---Summary of the training---------------------------------------
DEEPMD INFO running on: bohrium-21213-1088639
DEEPMD INFO computing device: cpu:0
DEEPMD INFO Count of visible GPU: 0
DEEPMD INFO num_intra_threads: 0
DEEPMD INFO num_inter_threads: 0
DEEPMD INFO -----------------------------------------------------------------
DEEPMD INFO ---Summary of DataSystem: training -----------------------------------------------
DEEPMD INFO found 1 system(s):
DEEPMD INFO system natoms bch_sz n_bch prob pbc
DEEPMD INFO ../00.data/training_data 5 7 23 1.000 T
DEEPMD INFO --------------------------------------------------------------------------------------
DEEPMD INFO ---Summary of DataSystem: validation -----------------------------------------------
DEEPMD INFO found 1 system(s):
DEEPMD INFO system natoms bch_sz n_bch prob pbc
DEEPMD INFO ../00.data/validation_data 5 7 5 1.000 T
DEEPMD INFO --------------------------------------------------------------------------------------
DEEPMD INFO training without frame parameter
DEEPMD INFO data stating... (this step may take long time)
DEEPMD INFO built lr
DEEPMD INFO built network
DEEPMD INFO built training
WARNING:root:To get the best performance, it is recommended to adjust the number of threads by setting the environment variables OMP_NUM_THREADS, TF_INTRA_OP_PARALLELISM_THREADS, and TF_INTER_OP_PARALLELISM_THREADS. See https://deepmd.rtfd.io/parallelism/ for more information.
DEEPMD INFO initialize model from scratch
DEEPMD INFO start training at lr 1.00e-03 (== 1.00e-03), decay_step 50, decay_rate 0.950006, final lr will be 3.51e-08
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/deepmd/train/trainer.py:1197: py_func (from tensorflow.python.ops.script_ops) is deprecated and will be removed in a future version.
Instructions for updating:
tf.py_func is deprecated in TF V2. Instead, there are two
options available in V2.
- tf.py_function takes a python function which manipulates tf eager
tensors instead of numpy arrays. It's easy to convert a tf eager tensor to
an ndarray (just call tensor.numpy()) but having access to eager tensors
means `tf.py_function`s can use accelerators such as GPUs as well as
being differentiable using a gradient tape.
- tf.numpy_function maintains the semantics of the deprecated tf.py_func
(it is not differentiable, and manipulates numpy arrays). It drops the
stateful argument making all functions stateful.
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/deepmd/train/trainer.py:1197: py_func (from tensorflow.python.ops.script_ops) is deprecated and will be removed in a future version.
Instructions for updating:
tf.py_func is deprecated in TF V2. Instead, there are two
options available in V2.
- tf.py_function takes a python function which manipulates tf eager
tensors instead of numpy arrays. It's easy to convert a tf eager tensor to
an ndarray (just call tensor.numpy()) but having access to eager tensors
means `tf.py_function`s can use accelerators such as GPUs as well as
being differentiable using a gradient tape.
- tf.numpy_function maintains the semantics of the deprecated tf.py_func
(it is not differentiable, and manipulates numpy arrays). It drops the
stateful argument making all functions stateful.
DEEPMD INFO batch 200 training time 17.53 s, testing time 0.05 s, total wall time 18.41 s
DEEPMD INFO batch 400 training time 14.96 s, testing time 0.05 s, total wall time 15.11 s
DEEPMD INFO batch 600 training time 15.47 s, testing time 0.05 s, total wall time 15.65 s
DEEPMD INFO batch 800 training time 14.25 s, testing time 0.04 s, total wall time 14.41 s
DEEPMD INFO batch 1000 training time 15.49 s, testing time 0.05 s, total wall time 15.65 s
DEEPMD INFO saved checkpoint model.ckpt
DEEPMD INFO batch 1200 training time 16.33 s, testing time 0.08 s, total wall time 17.33 s
DEEPMD INFO batch 1400 training time 14.31 s, testing time 0.05 s, total wall time 14.47 s
DEEPMD INFO batch 1600 training time 16.54 s, testing time 0.05 s, total wall time 16.72 s
DEEPMD INFO batch 1800 training time 16.90 s, testing time 0.09 s, total wall time 17.09 s
DEEPMD INFO batch 2000 training time 17.20 s, testing time 0.06 s, total wall time 17.37 s
DEEPMD INFO saved checkpoint model.ckpt
DEEPMD INFO batch 2200 training time 14.29 s, testing time 0.04 s, total wall time 14.83 s
DEEPMD INFO batch 2400 training time 13.11 s, testing time 0.04 s, total wall time 13.29 s
DEEPMD INFO batch 2600 training time 12.93 s, testing time 0.04 s, total wall time 13.08 s
DEEPMD INFO batch 2800 training time 14.58 s, testing time 0.04 s, total wall time 14.74 s
DEEPMD INFO batch 3000 training time 13.21 s, testing time 0.04 s, total wall time 13.35 s
DEEPMD INFO saved checkpoint model.ckpt
DEEPMD INFO batch 3200 training time 14.40 s, testing time 0.07 s, total wall time 15.14 s
DEEPMD INFO batch 3400 training time 13.08 s, testing time 0.04 s, total wall time 13.23 s
DEEPMD INFO batch 3600 training time 12.93 s, testing time 0.06 s, total wall time 13.13 s
DEEPMD INFO batch 3800 training time 15.23 s, testing time 0.05 s, total wall time 15.43 s
DEEPMD INFO batch 4000 training time 13.20 s, testing time 0.04 s, total wall time 13.35 s
DEEPMD INFO saved checkpoint model.ckpt
DEEPMD INFO batch 4200 training time 14.82 s, testing time 0.05 s, total wall time 16.06 s
DEEPMD INFO batch 4400 training time 14.26 s, testing time 0.05 s, total wall time 14.42 s
DEEPMD INFO batch 4600 training time 15.50 s, testing time 0.05 s, total wall time 15.66 s
DEEPMD INFO batch 4800 training time 14.12 s, testing time 0.05 s, total wall time 14.29 s
DEEPMD INFO batch 5000 training time 15.71 s, testing time 0.05 s, total wall time 15.88 s
DEEPMD INFO saved checkpoint model.ckpt
DEEPMD INFO batch 5200 training time 14.36 s, testing time 0.07 s, total wall time 15.40 s
DEEPMD INFO batch 5400 training time 15.77 s, testing time 0.05 s, total wall time 15.93 s
DEEPMD INFO batch 5600 training time 14.12 s, testing time 0.05 s, total wall time 14.29 s
DEEPMD INFO batch 5800 training time 15.53 s, testing time 0.04 s, total wall time 15.70 s
DEEPMD INFO batch 6000 training time 15.39 s, testing time 0.09 s, total wall time 15.58 s
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/tensorflow/python/training/saver.py:1066: remove_checkpoint (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.
Instructions for updating:
Use standard file APIs to delete files with this prefix.
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/tensorflow/python/training/saver.py:1066: remove_checkpoint (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.
Instructions for updating:
Use standard file APIs to delete files with this prefix.
DEEPMD INFO saved checkpoint model.ckpt
DEEPMD INFO batch 6200 training time 14.74 s, testing time 0.05 s, total wall time 15.64 s
DEEPMD INFO batch 6400 training time 15.24 s, testing time 0.09 s, total wall time 15.44 s
DEEPMD INFO batch 6600 training time 14.29 s, testing time 0.05 s, total wall time 14.48 s
DEEPMD INFO batch 6800 training time 15.46 s, testing time 0.09 s, total wall time 15.66 s
DEEPMD INFO batch 7000 training time 15.34 s, testing time 0.05 s, total wall time 15.54 s
DEEPMD INFO saved checkpoint model.ckpt
DEEPMD INFO batch 7200 training time 15.63 s, testing time 0.05 s, total wall time 16.19 s
DEEPMD INFO batch 7400 training time 14.71 s, testing time 0.06 s, total wall time 14.90 s
DEEPMD INFO batch 7600 training time 15.96 s, testing time 0.05 s, total wall time 16.12 s
DEEPMD INFO batch 7800 training time 19.68 s, testing time 0.06 s, total wall time 19.92 s
DEEPMD INFO batch 8000 training time 15.81 s, testing time 0.07 s, total wall time 16.00 s
DEEPMD INFO saved checkpoint model.ckpt
DEEPMD INFO batch 8200 training time 13.62 s, testing time 0.04 s, total wall time 14.54 s
DEEPMD INFO batch 8400 training time 13.23 s, testing time 0.04 s, total wall time 13.38 s
DEEPMD INFO batch 8600 training time 14.90 s, testing time 0.04 s, total wall time 15.08 s
DEEPMD INFO batch 8800 training time 13.19 s, testing time 0.04 s, total wall time 13.34 s
DEEPMD INFO batch 9000 training time 13.78 s, testing time 0.09 s, total wall time 14.00 s
DEEPMD INFO saved checkpoint model.ckpt
DEEPMD INFO batch 9200 training time 13.76 s, testing time 0.04 s, total wall time 14.41 s
DEEPMD INFO batch 9400 training time 13.06 s, testing time 0.04 s, total wall time 13.20 s
DEEPMD INFO batch 9600 training time 14.23 s, testing time 0.04 s, total wall time 14.42 s
DEEPMD INFO batch 9800 training time 13.72 s, testing time 0.05 s, total wall time 13.88 s
DEEPMD INFO batch 10000 training time 13.92 s, testing time 0.09 s, total wall time 14.12 s
DEEPMD INFO saved checkpoint model.ckpt
DEEPMD INFO average training time: 0.0737 s/batch (exclude first 200 batches)
DEEPMD INFO finished training
DEEPMD INFO wall time: 756.650 s
On the screen, you will see the information of the data system(s)
DEEPMD INFO -----------------------------------------------------------------
DEEPMD INFO ---Summary of DataSystem: training ----------------------------------
DEEPMD INFO found 1 system(s):
DEEPMD INFO system natoms bch_sz n_bch prob pbc
DEEPMD INFO ../00.data/training_data 5 7 23 1.000 T
DEEPMD INFO -------------------------------------------------------------------------
DEEPMD INFO ---Summary of DataSystem: validation ----------------------------------
DEEPMD INFO found 1 system(s):
DEEPMD INFO system natoms bch_sz n_bch prob pbc
DEEPMD INFO ../00.data/validation_data 5 7 5 1.000 T
DEEPMD INFO -------------------------------------------------------------------------
and the starting and final learning rate of this training
DEEPMD INFO start training at lr 1.00e-03 (== 1.00e-03), decay_step 50, decay_rate 0.950006, final lr will be 3.51e-08
If everything works fine, you will see, on the screen, information printed every 1000 steps, like
DEEPMD INFO batch 200 training time 6.04 s, testing time 0.02 s
DEEPMD INFO batch 400 training time 4.80 s, testing time 0.02 s
DEEPMD INFO batch 600 training time 4.80 s, testing time 0.02 s
DEEPMD INFO batch 800 training time 4.78 s, testing time 0.02 s
DEEPMD INFO batch 1000 training time 4.77 s, testing time 0.02 s
DEEPMD INFO saved checkpoint model.ckpt
DEEPMD INFO batch 1200 training time 4.47 s, testing time 0.02 s
DEEPMD INFO batch 1400 training time 4.49 s, testing time 0.02 s
DEEPMD INFO batch 1600 training time 4.45 s, testing time 0.02 s
DEEPMD INFO batch 1800 training time 4.44 s, testing time 0.02 s
DEEPMD INFO batch 2000 training time 4.46 s, testing time 0.02 s
DEEPMD INFO saved checkpoint model.ckpt
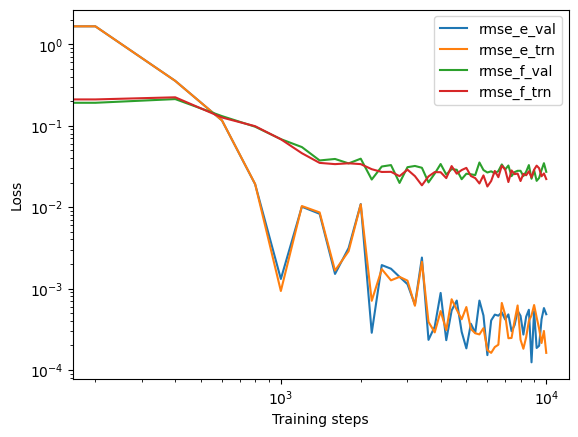
They present the training and testing time counts. At the end of the 1000th batch, the model is saved in TensorFlow’s checkpoint file model.ckpt. At the same time, the training and testing errors are presented in file lcurve.out.
The file contains 8 columns, form left to right, are the training step, the validation loss, training loss, root mean square (RMS) validation error of energy, RMS training error of energy, RMS validation error of force, RMS training error of force and the learning rate. The RMS error (RMSE) of the energy is normalized by number of atoms in the system.
head -n 2 lcurve.out
# step rmse_val rmse_trn rmse_e_val rmse_e_trn rmse_f_val rmse_f_trn lr
0 2.02e+01 1.51e+01 1.37e-01 1.41e-01 6.40e-01 4.79e-01 1.0e-03
and
$ tail -n 2 lcurve.out
9800 2.45e-02 4.02e-02 3.20e-04 3.88e-04 2.40e-02 3.94e-02 4.3e-08
10000 4.60e-02 3.76e-02 8.65e-04 5.35e-04 4.52e-02 3.69e-02 3.5e-08
Volumes 4, 5 and 6, 7 present energy and force training and testing errors, respectively.
! cd DeePMD-kit_Tutorial/01.train.finished/ && head -n 2 lcurve.out && tail -n 2 lcurve.out
# step rmse_val rmse_trn rmse_e_val rmse_e_trn rmse_f_val rmse_f_trn lr
0 1.79e+01 2.26e+01 1.35e-01 1.33e-01 5.67e-01 7.15e-01 1.0e-03
9800 3.53e-02 2.64e-02 5.75e-04 3.01e-04 3.46e-02 2.59e-02 4.3e-08
10000 2.76e-02 2.25e-02 4.83e-04 1.62e-04 2.71e-02 2.21e-02 3.5e-08
The loss function can be visualized to monitor the training process.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
with open("./DeePMD-kit_Tutorial/01.train.finished/lcurve.out") as f:
headers = f.readline().split()[1:]
lcurve = pd.DataFrame(
np.loadtxt("./DeePMD-kit_Tutorial/01.train.finished/lcurve.out"), columns=headers
)
legends = ["rmse_e_val", "rmse_e_trn", "rmse_f_val", "rmse_f_trn"]
for legend in legends:
plt.loglog(lcurve["step"], lcurve[legend], label=legend)
plt.legend()
plt.xlabel("Training steps")
plt.ylabel("Loss")
plt.show()
2.3.4. Freeze a model#
At the end of the training, the model parameters saved in TensorFlow’s checkpoint file should be frozen as a model file that is usually ended with extension .pb. Simply execute
## Navigate to the DeePMD-kit_Tutorial/01.train/ Directory to Freeze the Model
! cd DeePMD-kit_Tutorial/01.train.finished/ && dp freeze -o graph.pb
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/tensorflow/python/compat/v2_compat.py:107: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
non-resource variables are not supported in the long term
WARNING:root:To get the best performance, it is recommended to adjust the number of threads by setting the environment variables OMP_NUM_THREADS, TF_INTRA_OP_PARALLELISM_THREADS, and TF_INTER_OP_PARALLELISM_THREADS. See https://deepmd.rtfd.io/parallelism/ for more information.
DEEPMD WARNING The following nodes are not in the graph: {'fitting_attr/aparam_nall', 'spin_attr/ntypes_spin'}. Skip freezeing these nodes. You may be freezing a checkpoint generated by an old version.
DEEPMD INFO The following nodes will be frozen: ['descrpt_attr/rcut', 'model_attr/model_version', 'o_atom_virial', 'model_attr/tmap', 'model_attr/model_type', 'o_force', 'o_energy', 'train_attr/min_nbor_dist', 'model_type', 't_mesh', 'fitting_attr/daparam', 'train_attr/training_script', 'fitting_attr/dfparam', 'o_atom_energy', 'descrpt_attr/ntypes', 'o_virial']
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/deepmd/entrypoints/freeze.py:370: convert_variables_to_constants (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.convert_variables_to_constants`
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/deepmd/entrypoints/freeze.py:370: convert_variables_to_constants (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.convert_variables_to_constants`
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/tensorflow/python/framework/convert_to_constants.py:925: extract_sub_graph (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.extract_sub_graph`
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/tensorflow/python/framework/convert_to_constants.py:925: extract_sub_graph (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.extract_sub_graph`
DEEPMD INFO 1222 ops in the final graph.
and it will output a model file named graph.pb in the current directory.
2.3.5. Compress a model#
To enhance computational efficiency with DP models, compression significantly accelerates DP-based calculations and reduces memory usage. We can compress the model by running:
## Navigate to the DeePMD-kit_Tutorial/01.train/ Directory to Compress the Model
! cd DeePMD-kit_Tutorial/01.train.finished/ && dp compress -i graph.pb -o compress.pb
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/tensorflow/python/compat/v2_compat.py:107: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
non-resource variables are not supported in the long term
WARNING:root:To get the best performance, it is recommended to adjust the number of threads by setting the environment variables OMP_NUM_THREADS, TF_INTRA_OP_PARALLELISM_THREADS, and TF_INTER_OP_PARALLELISM_THREADS. See https://deepmd.rtfd.io/parallelism/ for more information.
DEEPMD INFO
DEEPMD INFO stage 1: compress the model
DEEPMD INFO _____ _____ __ __ _____ _ _ _
DEEPMD INFO | __ \ | __ \ | \/ || __ \ | | (_)| |
DEEPMD INFO | | | | ___ ___ | |__) || \ / || | | | ______ | | __ _ | |_
DEEPMD INFO | | | | / _ \ / _ \| ___/ | |\/| || | | ||______|| |/ /| || __|
DEEPMD INFO | |__| || __/| __/| | | | | || |__| | | < | || |_
DEEPMD INFO |_____/ \___| \___||_| |_| |_||_____/ |_|\_\|_| \__|
DEEPMD INFO Please read and cite:
DEEPMD INFO Wang, Zhang, Han and E, Comput.Phys.Comm. 228, 178-184 (2018)
DEEPMD INFO Zeng et al, J. Chem. Phys., 159, 054801 (2023)
DEEPMD INFO See https://deepmd.rtfd.io/credits/ for details.
DEEPMD INFO installed to: /root/miniconda3/envs/deepmd
DEEPMD INFO source : v2.2.7
DEEPMD INFO source branch: HEAD
DEEPMD INFO source commit: 839f4fe7
DEEPMD INFO source commit at: 2023-10-27 21:10:24 +0800
DEEPMD INFO build float prec: double
DEEPMD INFO build variant: cpu
DEEPMD INFO build with tf inc: /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/tensorflow/include;/root/miniconda3/envs/deepmd/lib/python3.10/site-packages/tensorflow/../../../../include
DEEPMD INFO build with tf lib:
DEEPMD INFO ---Summary of the training---------------------------------------
DEEPMD INFO running on: bohrium-21213-1088639
DEEPMD INFO computing device: cpu:0
DEEPMD INFO Count of visible GPU: 0
DEEPMD INFO num_intra_threads: 0
DEEPMD INFO num_inter_threads: 0
DEEPMD INFO -----------------------------------------------------------------
DEEPMD INFO training without frame parameter
DEEPMD INFO training data with lower boundary: [-0.92929175 -0.99957951]
DEEPMD INFO training data with upper boundary: [1.97058099 1.10195361]
DEEPMD INFO built lr
DEEPMD INFO built network
DEEPMD INFO built training
WARNING:root:To get the best performance, it is recommended to adjust the number of threads by setting the environment variables OMP_NUM_THREADS, TF_INTRA_OP_PARALLELISM_THREADS, and TF_INTER_OP_PARALLELISM_THREADS. See https://deepmd.rtfd.io/parallelism/ for more information.
DEEPMD INFO initialize model from scratch
DEEPMD INFO finished compressing
DEEPMD INFO
DEEPMD INFO stage 2: freeze the model
DEEPMD WARNING The following nodes are not in the graph: {'spin_attr/ntypes_spin', 'fitting_attr/aparam_nall'}. Skip freezeing these nodes. You may be freezing a checkpoint generated by an old version.
DEEPMD INFO The following nodes will be frozen: ['train_attr/min_nbor_dist', 'o_energy', 'descrpt_attr/rcut', 'o_force', 'model_type', 'fitting_attr/daparam', 'model_attr/tmap', 'o_atom_energy', 'descrpt_attr/ntypes', 'o_virial', 't_mesh', 'model_attr/model_type', 'fitting_attr/dfparam', 'o_atom_virial', 'train_attr/training_script', 'model_attr/model_version']
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/deepmd/entrypoints/freeze.py:370: convert_variables_to_constants (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.convert_variables_to_constants`
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/deepmd/entrypoints/freeze.py:370: convert_variables_to_constants (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.convert_variables_to_constants`
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/tensorflow/python/framework/convert_to_constants.py:925: extract_sub_graph (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.extract_sub_graph`
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/tensorflow/python/framework/convert_to_constants.py:925: extract_sub_graph (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.extract_sub_graph`
DEEPMD INFO 858 ops in the final graph.
2.3.6. Test a model#
We can check the quality of the trained model by running
! cd DeePMD-kit_Tutorial/01.train.finished/ && dp test -m graph.pb -s ../00.data/validation_data
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/tensorflow/python/compat/v2_compat.py:107: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
non-resource variables are not supported in the long term
WARNING:root:To get the best performance, it is recommended to adjust the number of threads by setting the environment variables OMP_NUM_THREADS, TF_INTRA_OP_PARALLELISM_THREADS, and TF_INTER_OP_PARALLELISM_THREADS. See https://deepmd.rtfd.io/parallelism/ for more information.
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/deepmd/utils/batch_size.py:62: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.config.list_physical_devices('GPU')` instead.
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/deepmd/utils/batch_size.py:62: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.config.list_physical_devices('GPU')` instead.
DEEPMD WARNING You can use the environment variable DP_INFER_BATCH_SIZE tocontrol the inference batch size (nframes * natoms). The default value is 1024.
DEEPMD INFO # ---------------output of dp test---------------
DEEPMD INFO # testing system : ../00.data/validation_data
DEEPMD INFO # number of test data : 40
DEEPMD INFO Energy MAE : 1.473845e-03 eV
DEEPMD INFO Energy RMSE : 2.007936e-03 eV
DEEPMD INFO Energy MAE/Natoms : 2.947689e-04 eV
DEEPMD INFO Energy RMSE/Natoms : 4.015871e-04 eV
DEEPMD INFO Force MAE : 2.146239e-02 eV/A
DEEPMD INFO Force RMSE : 2.748797e-02 eV/A
DEEPMD INFO Virial MAE : 2.879183e-02 eV
DEEPMD INFO Virial RMSE : 3.817983e-02 eV
DEEPMD INFO Virial MAE/Natoms : 5.758366e-03 eV
DEEPMD INFO Virial RMSE/Natoms : 7.635965e-03 eV
DEEPMD INFO # -----------------------------------------------
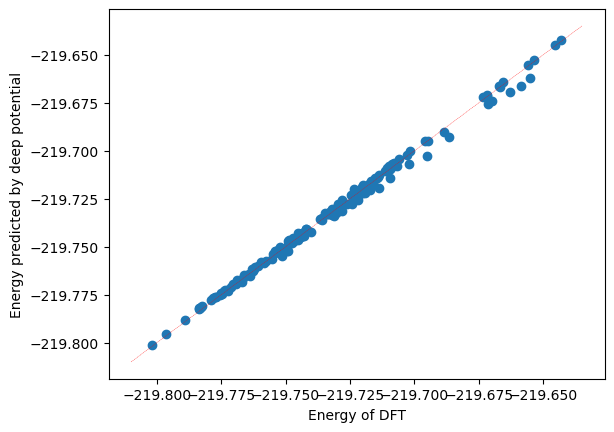
The correlation between predicted data and original data can also be calculated.
import dpdata
training_systems = dpdata.LabeledSystem(
"./DeePMD-kit_Tutorial/00.data/training_data", fmt="deepmd/npy"
)
predict = training_systems.predict("./DeePMD-kit_Tutorial/01.train.finished/graph.pb")
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/tensorflow/python/compat/v2_compat.py:107: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
non-resource variables are not supported in the long term
WARNING:root:To get the best performance, it is recommended to adjust the number of threads by setting the environment variables OMP_NUM_THREADS, TF_INTRA_OP_PARALLELISM_THREADS, and TF_INTER_OP_PARALLELISM_THREADS. See https://deepmd.rtfd.io/parallelism/ for more information.
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/deepmd/utils/batch_size.py:62: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.config.list_physical_devices('GPU')` instead.
2024-03-24 23:05:17.177887: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE4.1 SSE4.2 AVX AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-03-24 23:05:17.179243: I tensorflow/core/common_runtime/process_util.cc:146] Creating new thread pool with default inter op setting: 2. Tune using inter_op_parallelism_threads for best performance.
2024-03-24 23:05:17.197330: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:354] MLIR V1 optimization pass is not enabled
WARNING:tensorflow:From /root/miniconda3/envs/deepmd/lib/python3.10/site-packages/deepmd/utils/batch_size.py:62: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.config.list_physical_devices('GPU')` instead.
WARNING:deepmd.utils.batch_size:You can use the environment variable DP_INFER_BATCH_SIZE tocontrol the inference batch size (nframes * natoms). The default value is 1024.
import matplotlib.pyplot as plt
import numpy as np
plt.scatter(training_systems["energies"], predict["energies"])
x_range = np.linspace(plt.xlim()[0], plt.xlim()[1])
plt.plot(x_range, x_range, "r--", linewidth=0.25)
plt.xlabel("Energy of DFT")
plt.ylabel("Energy predicted by deep potential")
plt.plot()
[]
2.3.7. Run MD with LAMMPS#
The model can drive molecular dynamics in LAMMPS.
! ls
! cd ./DeePMD-kit_Tutorial/02.lmp && cp ../01.train.finished/graph.pb ./ && tree -L 1
DeePMD-kit_Tutorial
.
├── ch4.dump
├── conf.lmp
├── graph.pb
├── in.lammps
└── log.lammps
0 directories, 5 files
Here conf.lmp gives the initial configuration of a gas phase methane MD simulation, and the file in.lammps is the LAMMPS input script. One may check in.lammps and finds that it is a rather standard LAMMPS input file for a MD simulation, with only two exception lines:
pair_style deepmd graph.pb
pair_coeff * *
where the pair style deepmd is invoked and the model file graph.pb is provided, which means the atomic interaction will be computed by the DP model that is stored in the file graph.pb.
In an environment with a compatible version of LAMMPS, the deep potential molecular dynamics can be performed via
lmp -i input.lammps
! cd ./DeePMD-kit_Tutorial/02.lmp && lmp -i in.lammps
LAMMPS (2 Aug 2023 - Update 1)
OMP_NUM_THREADS environment is not set. Defaulting to 1 thread. (src/comm.cpp:98)
using 1 OpenMP thread(s) per MPI task
Loaded 1 plugins from /root/miniconda3/envs/deepmd/lib/deepmd_lmp
Reading data file ...
triclinic box = (0 0 0) to (10.114259 10.263124 10.216793) with tilt (0.036749877 0.13833062 -0.056322169)
1 by 1 by 1 MPI processor grid
reading atoms ...
5 atoms
read_data CPU = 0.002 seconds
DeePMD-kit WARNING: Environmental variable OMP_NUM_THREADS is not set. Tune OMP_NUM_THREADS for the best performance. See https://deepmd.rtfd.io/parallelism/ for more information.
Summary of lammps deepmd module ...
>>> Info of deepmd-kit:
installed to: /root/miniconda3/envs/deepmd
source: v2.2.7
source branch: HEAD
source commit: 839f4fe7
source commit at: 2023-10-27 21:10:24 +0800
support model ver.:1.1
build variant: cpu
build with tf inc: /root/miniconda3/envs/deepmd/include;/root/miniconda3/envs/deepmd/include
build with tf lib: /root/miniconda3/envs/deepmd/lib/libtensorflow_cc.so
set tf intra_op_parallelism_threads: 0
set tf inter_op_parallelism_threads: 0
>>> Info of lammps module:
use deepmd-kit at: /root/miniconda3/envs/deepmdDeePMD-kit WARNING: Environmental variable OMP_NUM_THREADS is not set. Tune OMP_NUM_THREADS for the best performance. See https://deepmd.rtfd.io/parallelism/ for more information.
2024-03-24 23:05:49.768736: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE4.1 SSE4.2 AVX AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-03-24 23:05:49.770401: I tensorflow/core/common_runtime/process_util.cc:146] Creating new thread pool with default inter op setting: 2. Tune using inter_op_parallelism_threads for best performance.
2024-03-24 23:05:49.817983: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:354] MLIR V1 optimization pass is not enabled
INVALID_ARGUMENT: Tensor spin_attr/ntypes_spin:0, specified in either feed_devices or fetch_devices was not found in the Graph
>>> Info of model(s):
using 1 model(s): graph.pb
rcut in model: 6
ntypes in model: 2
CITE-CITE-CITE-CITE-CITE-CITE-CITE-CITE-CITE-CITE-CITE-CITE-CITE
Your simulation uses code contributions which should be cited:
- USER-DEEPMD package:
The log file lists these citations in BibTeX format.
CITE-CITE-CITE-CITE-CITE-CITE-CITE-CITE-CITE-CITE-CITE-CITE-CITE
Generated 0 of 1 mixed pair_coeff terms from geometric mixing rule
Neighbor list info ...
update: every = 10 steps, delay = 0 steps, check = no
max neighbors/atom: 2000, page size: 100000
master list distance cutoff = 7
ghost atom cutoff = 7
binsize = 3.5, bins = 3 3 3
1 neighbor lists, perpetual/occasional/extra = 1 0 0
(1) pair deepmd, perpetual
attributes: full, newton on
pair build: full/bin/atomonly
stencil: full/bin/3d
bin: standard
Setting up Verlet run ...
Unit style : metal
Current step : 0
Time step : 0.001
Per MPI rank memory allocation (min/avg/max) = 2.559 | 2.559 | 2.559 Mbytes
Step PotEng KinEng TotEng Temp Press Volume
0 -219.77409 0.025852029 -219.74824 50 -799.80566 1060.5429
100 -219.77101 0.02250472 -219.7485 43.526023 -563.15562 1060.5429
200 -219.77525 0.025722761 -219.74953 49.749984 -55.768826 1060.5429
300 -219.78111 0.030123111 -219.75098 58.260632 415.50143 1060.5429
400 -219.78545 0.03264184 -219.7528 63.132067 724.77655 1060.5429
500 -219.7897 0.034591934 -219.75511 66.903712 664.01323 1060.5429
600 -219.78944 0.031599794 -219.75784 61.116661 307.82983 1060.5429
700 -219.78389 0.023121639 -219.76076 44.719197 -166.66606 1060.5429
800 -219.77712 0.013122374 -219.764 25.379775 -493.10259 1060.5429
900 -219.7791 0.011293959 -219.76781 21.843468 -609.86395 1060.5429
1000 -219.78712 0.01531002 -219.77181 29.610866 -422.5828 1060.5429
1100 -219.7939 0.018709632 -219.77519 36.186003 -61.443156 1060.5429
1200 -219.79395 0.016606919 -219.77734 32.11918 331.62678 1060.5429
1300 -219.79132 0.012642575 -219.77868 24.451803 505.6361 1060.5429
1400 -219.79314 0.013255468 -219.77989 25.637191 381.73541 1060.5429
1500 -219.79509 0.014397006 -219.78069 27.845022 48.696022 1060.5429
1600 -219.79313 0.012485864 -219.78064 24.148711 -302.67659 1060.5429
1700 -219.78841 0.0085717658 -219.77983 16.578516 -476.08062 1060.5429
1800 -219.78663 0.0081557171 -219.77847 15.773843 -407.83792 1060.5429
1900 -219.78715 0.010996426 -219.77615 21.268013 -98.699573 1060.5429
2000 -219.78836 0.016278673 -219.77209 31.484324 293.02315 1060.5429
2100 -219.78819 0.022161035 -219.76603 42.861306 587.40225 1060.5429
2200 -219.79165 0.031838471 -219.75981 61.578284 543.58893 1060.5429
2300 -219.79343 0.038239208 -219.75519 73.957846 104.54643 1060.5429
2400 -219.78301 0.031060153 -219.75195 60.072951 -293.72903 1060.5429
2500 -219.77209 0.022352657 -219.74974 43.231919 -606.61353 1060.5429
2600 -219.76604 0.017305685 -219.74873 33.47065 -623.66583 1060.5429
2700 -219.77552 0.026563069 -219.74895 51.375211 -332.34033 1060.5429
2800 -219.78594 0.0362724 -219.74967 70.153875 120.73427 1060.5429
2900 -219.78868 0.038558744 -219.75012 74.575856 542.93567 1060.5429
3000 -219.78351 0.03281317 -219.75069 63.463433 746.24646 1060.5429
3100 -219.78106 0.028937414 -219.75212 55.967395 583.87016 1060.5429
3200 -219.77929 0.025275432 -219.75402 48.884814 128.24387 1060.5429
3300 -219.77781 0.022017978 -219.75579 42.584622 -395.55332 1060.5429
3400 -219.77696 0.019305132 -219.75765 37.33775 -679.74745 1060.5429
3500 -219.78369 0.023714356 -219.75997 45.86556 -656.9891 1060.5429
3600 -219.79244 0.030071312 -219.76237 58.160448 -354.34542 1060.5429
3700 -219.79168 0.027557568 -219.76412 53.298657 199.00964 1060.5429
3800 -219.78639 0.021137515 -219.76525 40.881734 596.54224 1060.5429
3900 -219.77923 0.012972221 -219.76626 25.089367 713.41996 1060.5429
4000 -219.78185 0.014202505 -219.76765 27.46884 430.83529 1060.5429
4100 -219.78477 0.016041208 -219.76872 31.025047 -28.605377 1060.5429
4200 -219.78545 0.016332231 -219.76912 31.587909 -457.5328 1060.5429
4300 -219.78602 0.016882726 -219.76914 32.652612 -608.55966 1060.5429
4400 -219.78949 0.020680419 -219.76881 39.99767 -456.72943 1060.5429
4500 -219.79121 0.023411938 -219.7678 45.280658 -79.406734 1060.5429
4600 -219.7882 0.022574198 -219.76562 43.660398 414.11955 1060.5429
4700 -219.78521 0.022736692 -219.76248 43.974676 663.73939 1060.5429
4800 -219.7834 0.025050214 -219.75835 48.449222 598.39611 1060.5429
4900 -219.78291 0.030199797 -219.75271 58.408949 203.75805 1060.5429
5000 -219.77611 0.030245158 -219.74586 58.496682 -300.80549 1060.5429
Loop time of 38.8363 on 1 procs for 5000 steps with 5 atoms
Performance: 11.124 ns/day, 2.158 hours/ns, 128.746 timesteps/s, 643.728 atom-step/s
104.3% CPU use with 1 MPI tasks x 1 OpenMP threads
MPI task timing breakdown:
Section | min time | avg time | max time |%varavg| %total
---------------------------------------------------------------
Pair | 38.703 | 38.703 | 38.703 | 0.0 | 99.66
Neigh | 0.0079815 | 0.0079815 | 0.0079815 | 0.0 | 0.02
Comm | 0.0334 | 0.0334 | 0.0334 | 0.0 | 0.09
Output | 0.0065195 | 0.0065195 | 0.0065195 | 0.0 | 0.02
Modify | 0.070599 | 0.070599 | 0.070599 | 0.0 | 0.18
Other | | 0.01491 | | | 0.04
Nlocal: 5 ave 5 max 5 min
Histogram: 1 0 0 0 0 0 0 0 0 0
Nghost: 130 ave 130 max 130 min
Histogram: 1 0 0 0 0 0 0 0 0 0
Neighs: 0 ave 0 max 0 min
Histogram: 1 0 0 0 0 0 0 0 0 0
FullNghs: 20 ave 20 max 20 min
Histogram: 1 0 0 0 0 0 0 0 0 0
Total # of neighbors = 20
Ave neighs/atom = 4
Neighbor list builds = 500
Dangerous builds not checked
Total wall time: 0:00:39