4.5. Descriptor "se_atten" 



 #
#
Note
Supported backends: TensorFlow , PyTorch , JAX , Paddle , DP ![]()
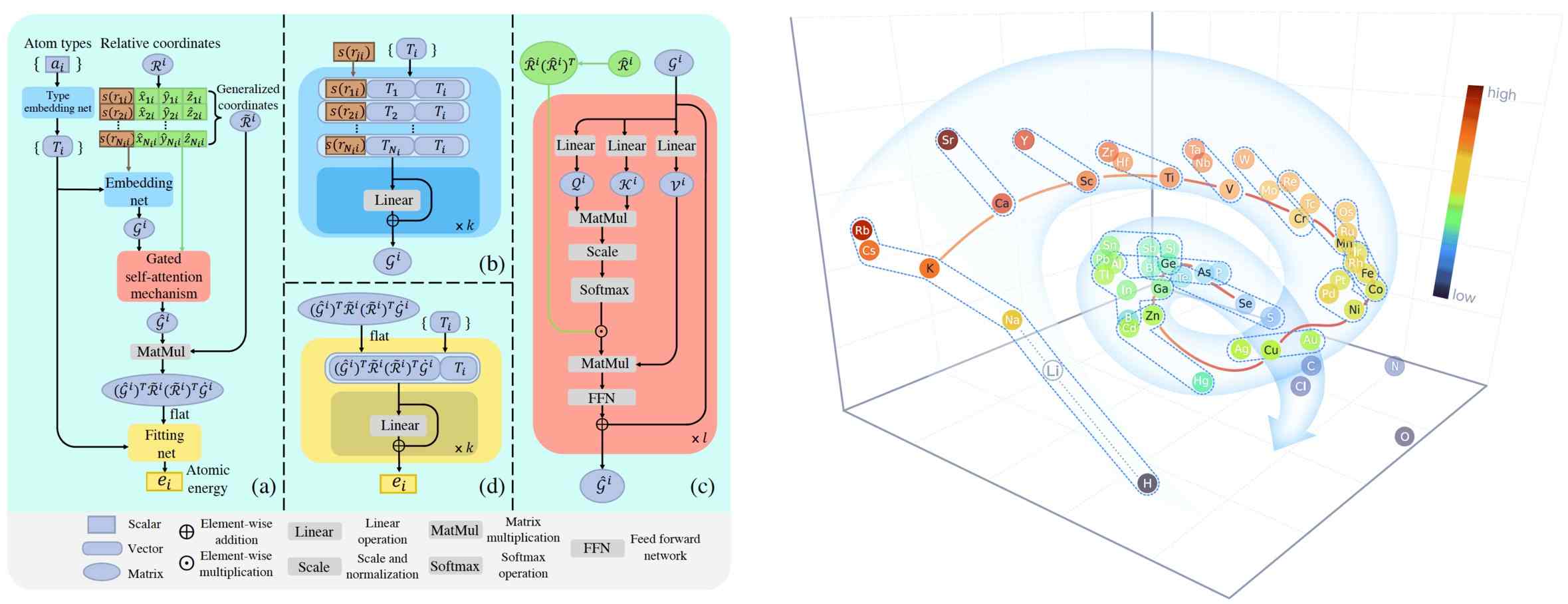
Here we propose DPA-1, a Deep Potential model with a novel attention mechanism, which is highly effective for representing the conformation and chemical spaces of atomic systems and learning the PES.
See this paper for more information. DPA-1 is implemented as a new descriptor "se_atten" for model training, which can be used after simply editing the input.json.
4.5.1. Theory#
Attention-based descriptor \(\mathcal{D}^i \in \mathbb{R}^{M \times M_{<}}\), which is proposed in pretrainable DPA-1 model, is given by
where \(\hat{\mathcal{G}}^i\) represents the embedding matrix \(\mathcal{G}^i\) after additional self-attention mechanism and \(\mathcal{R}^i\) is defined by the full case in the se_e2_a. Note that we obtain \(\mathcal{G}^i\) using the type embedding method by default in this descriptor. By default, we concat \(s(r_{ij})\) and the type embeddings of central and neighboring atoms \(\mathcal{A}^i\) and \(\mathcal{A}^j\) as input of the embedding network \(\mathcal{N}_{e,2}\):
To perform the self-attention mechanism, the queries \(\mathcal{Q}^{i,l} \in \mathbb{R}^{N_c\times d_k}\), keys \(\mathcal{K}^{i,l} \in \mathbb{R}^{N_c\times d_k}\), and values \(\mathcal{V}^{i,l} \in \mathbb{R}^{N_c\times d_v}\) are first obtained:
where \(Q_{l}\), \(K_{l}\), \(V_{l}\) represent three trainable linear transformations that output the queries and keys of dimension \(d_k\) and values of dimension \(d_v\), and \(l\) is the index of the attention layer. The input embedding matrix to the attention layers, denoted by \(\mathcal{G}^{i,0}\), is chosen as the two-body embedding matrix.
Then the scaled dot-product attention method is adopted:
where \(\varphi\left(\mathcal{Q}^{i,l}, \mathcal{K}^{i,l},\mathcal{R}^{i,l}\right) \in \mathbb{R}^{N_c\times N_c}\) is attention weights. In the original attention method, one typically has \(\varphi\left(\mathcal{Q}^{i,l}, \mathcal{K}^{i,l}\right)=\mathrm{softmax}\left(\frac{\mathcal{Q}^{i,l} (\mathcal{K}^{i,l})^{T}}{\sqrt{d_{k}}}\right)\), with \(\sqrt{d_{k}}\) being the normalization temperature. This is slightly modified to incorporate the angular information:
where \(\hat{\mathcal{R}}^{i} \in \mathbb{R}^{N_c\times 3}\) denotes normalized relative coordinates , \(\hat{\mathcal{R}}^{i}_{j} = \frac{\boldsymbol{r}_{ij}}{\lVert \boldsymbol{r}_{ij} \lVert}\) and \(\odot\) means element-wise multiplication.
Then layer normalization is added in a residual way to finally obtain the self-attention local embedding matrix \(\hat{\mathcal{G}}^{i} = \mathcal{G}^{i,L_a}\) after \(L_a\) attention layers:[1]
4.5.2. Descriptor "se_atten"#
Next, we will list the detailed settings in input.json and the data format, especially for large systems with dozens of elements. An example of DPA-1 input can be found in examples/water/se_atten/input.json.
The notation of se_atten is short for the smooth edition of Deep Potential with an attention mechanism. This descriptor was described in detail in the DPA-1 paper and the images above.
In this example, we will train a DPA-1 model for a water system. A complete training input script of this example can be found in the directory:
$deepmd_source_dir/examples/water/se_atten/input.json
With the training input script, data are also provided in the example directory. One may train the model with the DeePMD-kit from the directory.
An example of the DPA-1 descriptor is provided as follows
"descriptor" :{
"type": "se_atten",
"rcut_smth": 0.50,
"rcut": 6.00,
"sel": 120,
"neuron": [25, 50, 100],
"axis_neuron": 16,
"resnet_dt": false,
"attn": 128,
"attn_layer": 2,
"attn_mask": false,
"attn_dotr": true,
"seed": 1
}
The type of the descriptor is set to
"se_atten", which will use DPA-1 structures.rcut is the cut-off radius for neighbor searching, and the rcut_smth gives where the smoothing starts.
sel gives the maximum possible number of neighbors in the cut-off radius. It is an int. Note that this number highly affects the efficiency of training, which we usually use less than 200. (We use 120 for training 56 elements in OC2M dataset)
The neuron specifies the size of the embedding net. From left to right the members denote the sizes of each hidden layer from the input end to the output end, respectively. If the outer layer is twice the size of the inner layer, then the inner layer is copied and concatenated, then a ResNet architecture is built between them.
The axis_neuron specifies the size of the submatrix of the embedding matrix, the axis matrix as explained in the DeepPot-SE paper
If the option resnet_dt is set to
true, then a timestep is used in the ResNet.seed gives the random seed that is used to generate random numbers when initializing the model parameters.
attn sets the length of a hidden vector during scale-dot attention computation.
attn_layer sets the number of layers in attention mechanism.
attn_mask determines whether to mask the diagonal in the attention weights and False is recommended.
attn_dotr determines whether to dot the relative coordinates on the attention weights as a gated scheme, True is recommended.
4.5.2.1. Descriptor "se_atten_v2"#
We highly recommend using the version 2.0 of the attention-based descriptor "se_atten_v2", which is inherited from "se_atten" but with the following parameter modifications:
"tebd_input_mode": "strip",
"smooth_type_embedding": true,
"set_davg_zero": false
You can use descriptor "se_atten_v2" and is not allowed to set tebd_input_mode and smooth_type_embedding. In "se_atten_v2", tebd_input_mode is forced to be "strip" and smooth_type_embedding is forced to be "true". When tebd_input_mode is "strip", the embedding matrix \(\mathcal{G}^i\) is constructed as:
Practical evidence demonstrates that "se_atten_v2" offers better and more stable performance compared to "se_atten".
Note
Model compression support differs across backends. See Model compression for backend-specific requirements.
4.5.3. Type embedding#
DPA-1 only supports models with type embeddings.
In the TensorFlow backend, the type_embedding section will be used. If it is not set, the following default parameters will be used:
"type_embedding":{
"neuron": [8],
"resnet_dt": false,
"seed": 1
}
In other backends, type embedding is within this descriptor with the tebd_dim argument.
4.5.4. Difference among different backends#
TensorFlow and other backends have different implementations for smooth_type_embedding. The results are inconsistent when smooth_type_embedding is true.
In the TensorFlow backend, scaling_factor cannot set to a value other than 1.0; normalize cannot be set to false; temperature cannot be set; concat_output_tebd cannot be set to false.
4.5.5. Type map#
For training large systems, especially those with dozens of elements, the type determines the element index of training data:
"type_map": [
"Mg",
"Al",
"Cu"
]
which should include all the elements in the dataset you want to train on.
4.5.6. Data format#
DPA-1 supports both the standard data format and the mixed type data format.
4.5.7. Model compression#
4.5.7.1. TensorFlow #
Model compression is supported only when the descriptor attention depth attn_layer is 0 and tebd_input_mode is "strip". Attention layers higher than 0 cannot be compressed in the TensorFlow implementation because the geometric part is tabulated from the static computation graph.
4.5.7.2. PyTorch #
Model compression is supported for any attn_layer value when tebd_input_mode is "strip". When attn_layer is 0, both the type embedding and geometric parts are compressed. When attn_layer is not 0, only the type embedding is compressed while the geometric part keeps the neural network implementation (a warning is emitted during compression).
4.5.8. Training example#
Here we upload the AlMgCu example shown in the paper, you can download it here: Baidu disk; Google disk.