Support DPDispatcher on Yarn#
Background#
Currently, DPGen(or other DP software) supports for HPC systems like Slurm, PBS, LSF and cloud machines. In order to run DPGen jobs on ByteDance internal platform, we need to extend it to support yarn resources. Hadoop Ecosystem is a very commonly used platform to process the big data, and in the process of developing the new interface, we found it can be implemented by only using hadoop opensource components. So for the convenience of the masses, we decided to contribute the codes to opensource community.
Design#
We use DistributedShell and HDFS to implement it. The control flow shows as follows: 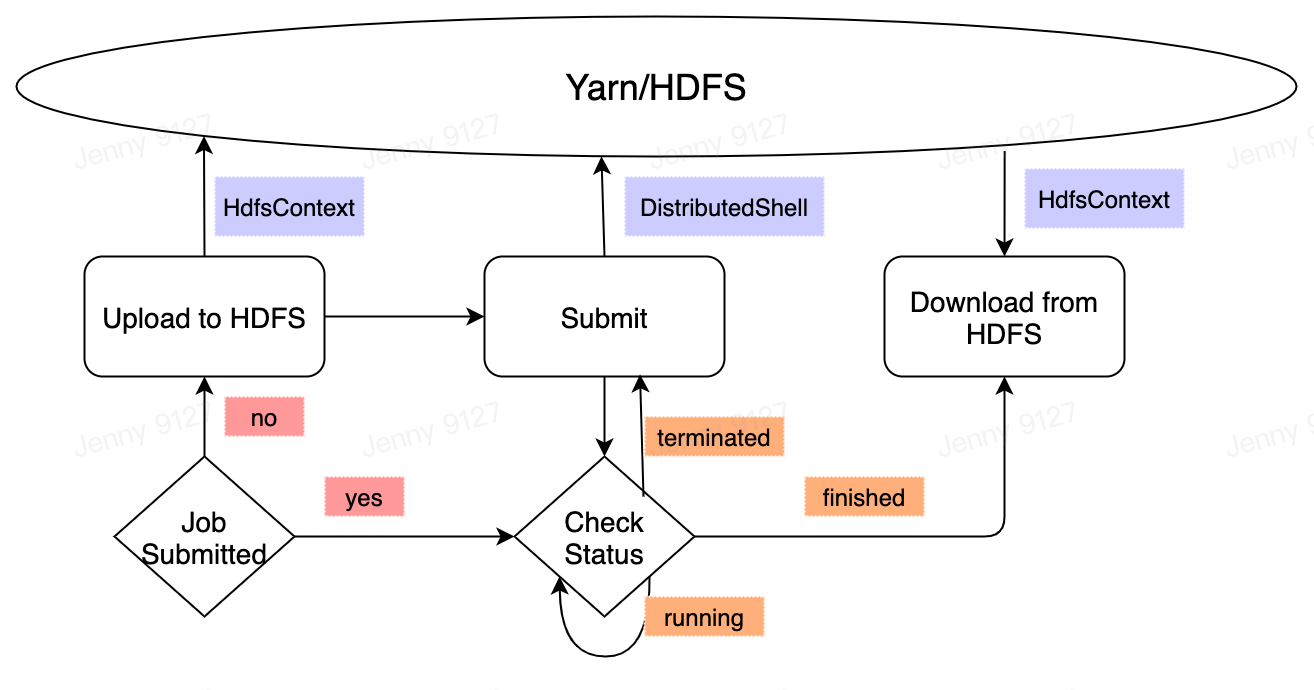
Use DistributedShell to submit yarn jobs. It contains generating shell script and submitting it to yarn queues.
Use HDFS to save input files and output results. For performance reasons, we choose to pack forward files to a tar.gz file and upload it to HDFS directory. Accordingly, the task will download the tar file before running and upload result tar file to HDFS after it has done.
Implement#
We only need to add two Class which are HDFSContext and DistributedShell:
class HDFSContext(BaseContext) :
def upload(self, job_dirs, local_up_files):
""" upload forward files and forward command files to HDFS root dir
Parameters
----------
job_dirs : list
the dictionary which contains the upload files
local_up_files: list
the file names which will be uploaded
Returns
-------
none
"""
pass
def download(self, submission):
""" download backward files from HDFS root dir
Parameters
----------
submission : Submission class instance
represents a collection of tasks, such as backward file names
Returns
-------
none
"""
pass
def check_file_exists(self, fname):
""" check whether the given file exists, often used in checking whether the belonging job has finished
Parameters
----------
fname : string
file name to be checked
Returns
-------
status: boolean
"""
pass
class DistributedShell(Machine):
def do_submit(self, job):
""" submit th job to yarn using distributed shell
Parameters
----------
job : Job class instance
job to be submitted
Returns
-------
job_id: string
usually a yarn application id
"""
pass
def check_status(self, job):
""" check the yarn job status
Parameters
----------
job : Job class instance
the submitted job
Returns
-------
status: JobStatus
"""
pass
def gen_script_command(self, job):
""" Generate the shell script to be executed in DistributedShell container
Parameters
----------
job : Job class instance
the submitted job
Returns
-------
script: string
script command string
"""
pass
The following is an example of generated shell script. It will be executed in a yarn container:
#!/bin/bash
## set environment variables
source /opt/intel/oneapi/setvars.sh
## download the tar file from hdfs which contains forward files
if ! ls uuid_upload_*.tgz 1>/dev/null 2>&1; then
hadoop fs -get /root/uuid/uuid_upload_*.tgz .
fi
for tgz_file in `ls *.tgz`; do tar xvf $tgz_file; done
## check whether the task has finished successfully
hadoop fs -test -e /root/uuid/sys-0001-0015/tag_0_finished
{ if [ ! $? -eq 0 ] ;then
cur_dir=`pwd`
cd t sys-0001-0015
test $? -ne 0 && exit 1
## do your job here
mpirun -n 32 vasp_std 1>> log 2>> err
if test $? -ne 0; then
exit 1
else
hadoop fs -touchz /root/uuid/sys-0001-0015/tag_0_finished
fi
cd $cur_dir
test $? -ne 0 && exit 1
fi }&
wait
## upload result files to hdfs
tar czf uuid_download.tar.gz sys-0001-0015
hadoop fs -put -f uuid_download.tar.gz /root/uuid/sys-0001-0015
## mark the job has finished
hadoop fs -touchz /root/uuid/uuid_tag_finished
An example of machine.json is as follows, whose batch_type is DistributedShell,and context_type is HDFSContext:
"fp": [
{
"command": "mpirun -n 32 vasp_std",
"machine": {
"batch_type": "DistributedShell",
"context_type": "HDFSContext",
"local_root": "./",
"remote_root": "hdfs://path/to/remote/root"
},
"resources": {
"number_node": 1,
"cpu_per_node": 32,
"gpu_per_node": 0,
"queue_name": "queue_name",
"group_size": 1,
"source_list": ["/opt/intel/oneapi/setvars.sh"],
"kwargs": {
"img_name": "",
"mem_limit": 32,
"yarn_path": "/path/to/yarn/jars"
},
"envs" : {
"HADOOP_HOME" : "${HADOOP_HOME:/path/to/hadoop/bin}",
"CLASSPATH": "`${HADOOP_HOME}/bin/hadoop classpath --glob`",
"PATH": "${HADOOP_HOME}/bin:${PATH}"}
}
}
}
]